Yaroslav O. Halchenko Barak A. Pearlmutter
Department of Computer Science
University of New Mexico
Albuquerque, NM 87131, USA
The problem of joint approximate diagonalization of a set of matrices is important in source separation, and a number of efficient methods for JAD have been developed. Pham and Cardoso (2000) and Cardoso and Souloumiac (1996) use Jacobi-like techniques to diagonalize a set of matrices through unitary transformation, following a prewhitening step. Pham (1999) also uses a Jacobi approach, operating on pairs of rows and columns at each step. In general, all Jacobi-based methods operate on pairs of columns and rows at each step, which can (Zumbuddy, 1923) state about some overshoot in computational expenses.
The original AC-DC algorithm (Yeredor, 2002) also operates only on Hermitian or symmetric matrices. It involves the computation of the largest eigenvalue and corresponding eigenvector at each AC step of the algorithm. As we see, many existing methods rely on the fact that matrices to be diagonalized are Hermitian, which in fact holds for many practical tasks -- symmetry comes from the fact that matrices to be diagonalized are typically covariance matrices or matrices of cummulants. These JAD methods are widely used in construction of different frameworks for separating signals in ICA problems.
The tree-decorrelation algorithm (Zibulevsky and Pearlmutter, 2000) also relies on computing an eigenspace for each matrix at each step, and makes use of the noise induced in the resulting eigenvalues by noise in the matrices input to the algorithm. Even if joint diagonalization is not the direct target of the work and is not mentioned as a criterion, it is known from PCA analysis that eigenvectors find minimum quadratic error solutions, and the tree-decorrelation method uses this property to minimize the off-diagonal entries of the transformed covariance matrices.
Here we derive a simple gradient descent rule for optimizing the criterion (2) derived below. Natural gradient descent (Amari, 1998) can be used to improve the performance by making the optimization covariant. Because the convergence of proposed method is no faster than existing methods, and convergence to the global minimum is not guaranteed, the method can be used as a simple fine-tuning mechanism for other ``fast'' algorithms which reach their optimum near1local minimum of the optimized criterion.
??? Is this true? Ie do these methods find the global optimum?
!!! actually youre right - they don't promise convergence to
the global minimum. Pham's paper says explicitly that criterion
can have several (fixed number) of local minimums. Cardoso's old
method for diagonalization (the one in JADE) seems to bring to the
global minimum of the criterion while working on presphered data.
So main error is introduced by presphering as I mentioned in
footnote
Do they converge as quickly as gradient methods? At ICA-2001
Cardoso told me that gradient methods should be faster.I've not
done any convergence analysis but all methods which I've
considered converge much faster and even have quadratic
convergence as Pham mentioned. In this paper we derived just
simple gradient method and main problem is that on each step to
compute gradient I need to do a lot of matrix multiplications.
Probably if we approximate it somehow to avoid that, we gain a lot
of speed-up, but for now it is
computationally intensive
We also need to add something about this method not constraining
solution to perfectly diagonalize a particular covariance matrix,
and therefore expanding the solution space to include potentially
better separations. but isn't it a question of having
presphering? so Cardoso already gave analysis how badly
presphering can influence on the result in (Cardoso, 1994).
Pham's method also doesn't use presphering, so it is also gives
potentially better
results.
Maybe give an example, eg if all the matrices are contaminated by
the same amount of noise it would raise the error if we singled out
one for special treatment.Ok - will be done. Will include
comparison between our, Cardoso's and Phams diagonalizers
We wish to diagonalize set of real-valued
![]() matrices
matrices
![]() . We adopt the usual quality criterion
for diagonalization, namely the sum of the squares of off-diagonal
elements, subject to a constraint to keep the diagonal elements from
also going to zero. For this purpose we define
. We adopt the usual quality criterion
for diagonalization, namely the sum of the squares of off-diagonal
elements, subject to a constraint to keep the diagonal elements from
also going to zero. For this purpose we define
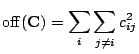 |
(1) |
We must enforce a constraint to prevent
![]() from being a solution.
One approach is to project the solution back onto a suitable manifold
after each unconstrained optimization step, for instance by
re-normalizing each row at each step. Another is to directly fix the
norm of
from being a solution.
One approach is to project the solution back onto a suitable manifold
after each unconstrained optimization step, for instance by
re-normalizing each row at each step. Another is to directly fix the
norm of
![]() using one of the methods described by
Douglas et al. (1999). In the spirit of Bell and Sejnowski (1995),
we instead use a Lagrange multiplier on the logarithm of the absolute
value of the determinant, which prevents
using one of the methods described by
Douglas et al. (1999). In the spirit of Bell and Sejnowski (1995),
we instead use a Lagrange multiplier on the logarithm of the absolute
value of the determinant, which prevents
![]() from becoming
singular.2Using this approach we obtain a criterion suitable for unconstrained
minimization,
from becoming
singular.2Using this approach we obtain a criterion suitable for unconstrained
minimization,
Taking the derivative (see Appendix A) leads to
With the gradient (4) in hand we can use any suitable gradient optimization method to minimize (3). The experimental results below were obtained using simple steepest descent. This technique has the advantage of simplicity, but is not in general very efficient. To increase stability and improve convergence we can instead use the natural gradient (Amari, 1998) to make this algorithm covariant and to avoid matrix inversion in computation of the derivative.
In case if Lagrange multiplier
![]() is used to constrain
is used to constrain
![]() from becoming singular, we also would like to avoid using
gradient descent merely to re-scale
from becoming singular, we also would like to avoid using
gradient descent merely to re-scale
![]() to reach a saddle point
between the two components of (3), for which we
introduce a projection operation to be performed once before
optimization begins,
to reach a saddle point
between the two components of (3), for which we
introduce a projection operation to be performed once before
optimization begins,
??? Was this projection used or not? If so, why bother with the
log det term? Good point. So corrected paper and algorithm.
May be it is better just to use rescaling of
![]() without even
usage of Lagrange multiplier Was natural gradient used, or not?
And what exactly is the natural gradient equation? This is very
confusing.I'm confused too. In sense that don't know if usual
without even
usage of Lagrange multiplier Was natural gradient used, or not?
And what exactly is the natural gradient equation? This is very
confusing.I'm confused too. In sense that don't know if usual
![]() is applicable to our optimization rule, cause our criterion
space can be totally different from the others used in ICA and for
which it was proven to work - will check on practice and adjust an
article then
is applicable to our optimization rule, cause our criterion
space can be totally different from the others used in ICA and for
which it was proven to work - will check on practice and adjust an
article then
These numerical experiments used data from Pham and Cardoso (2000), to which Prof. Cardoso was kind enough to give us access. There are three speech waveforms sampled at 8 kHz in this data set. About 2000 ms of speech are available for each speaker: one male, one female, and one child. The non-stationarity of these signals is used in Section 4.2, but is not important for the results of Section 4.1, which merely compares the diagonalization results obtained by various algorithms.
??? Why is this section called ``Diagonalization''? Isn't that the subject of the whole paper?
This proposed algorithm can be used for fine-tuning results obtained with algorithms which introduce some constraints, for instance requiring presphering of the data.
Matrices for diagonalization used in these experiment were obtained as
covariance matrices between synthetic sensor signals, with some delays
(![]() 0:10 12:2:20 25:5:100 110:10:200
0:10 12:2:20 25:5:100 110:10:200![]() 0.125
0.125 ![]() , in Matlab
notation.) The covariance matrices for specific
, in Matlab
notation.) The covariance matrices for specific ![]() were symmetrized
to give the set of matrices
were symmetrized
to give the set of matrices
![]() using
using
![]()
Cardoso's JAD method and Pham's BGML method were used to check
off-diagonality criterion (2) and served as a starting
point to refine separating matrix using our iterative steepest descent
algorithm. To compare performance of different algorithms, the final
unmixing matrices were row-scaled to give 1's on the diagonal of
![]() , the zero-delay covariance matrix of the separated sources.
, the zero-delay covariance matrix of the separated sources.
As shown in Figure 1, Cardoso's method did not give good results, probably due to its presphering step. Our gradient algorithm therefore frequently converged to a local minimum when started far from the right solution. Pham's method, which is based on a different criterion, gave much better results. Further refinement of the output of Pham's algorithm using the gradient method proposed here allowed us to lower the off-diagonality criterion to nearly that of the original unmixed signals.
![\includegraphics[width=0.8\textwidth]{cmp_offdiag.eps}](img39.png) |
We applied our algorithm to separate data online, as in Pham and Cardoso (2000). Our steepest gradient descent algorithm was not as fast as the Jacobi-like rotations of Pham and Cardoso (2000), but proper tuning of the learning parameters (learning step and error threshold) could improve it for specific examples, so the introduction of modern stochastic gradient methods (Schraudolph, 2002) should give enormous acceleration.
Running code obtained from Pham and Cardoso (2000) with the same parameters
(speech signals, a block length of 320 samples (40 ms), and a memory
of last ![]() covariance matrices to consider) but using our
diagonalizer (
covariance matrices to consider) but using our
diagonalizer (
![]() , error threshold =
, error threshold = ![]() and
and
![]() ) and scaling the rows to give a unit diagonal, we obtained
) and scaling the rows to give a unit diagonal, we obtained
![$\displaystyle \hat{\mathbf{B}}\mathbf{A}= \left[\begin{array}{r@{}lr@{}lr@{}l} ...
...&.0023 & 1&.0000 & -0&.0006 \ -0&.0218 & 0&.0100 & 1&.0000 \end{array} \right]$](img44.png) |
(7) |
Figure 2 shows the convergence of the on-line version of JD-BGL and the same procedure but with usage of our diagonalization algorithm. It is easy to see that our algorithm converged close to solution even earlier than JD-BGL. So when JD-BGL gives better result in general, simple criterion (2) needs less data (covariance matrices) to give plausible results.
![\includegraphics[width=\columnwidth]{TestOnlineGrad0}](img46.png)
![\includegraphics[width=\columnwidth]{TestOnlineBGML}](img47.png) |
Supported in part by NSF CAREER award 97-02-311, the Mental Illness and Neuroscience Discovery Institute, and a gift from the NEC Research Institute.
First let's find derivative
![]() , where
, where
![]() (we omit index
(we omit index ![]() for
for
![]() matrices for now). To simplify notation
and avoid usage of Kronecker product we find
matrices for now). To simplify notation
and avoid usage of Kronecker product we find
where
![]() is elementary matrix - zero everywhere besides
is elementary matrix - zero everywhere besides
![]() element 3. So
element 3. So
![]() has
only one
has
only one ![]() th and
th and ![]() th column non empty and the rest of numbers just
0s.
th column non empty and the rest of numbers just
0s.
Off-diagonal criterion
![]() would
lead to the derivative
would
lead to the derivative
Equation (9) simplifies to the next one because as it
was said each
![]() has just single non-zero column
and row.
has just single non-zero column
and row.
Finally combining gotten result into derivative of whole criterion (3) we get the result (4).
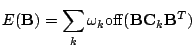
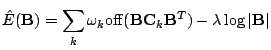
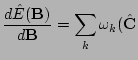 off
off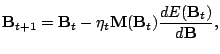
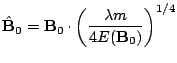
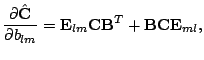
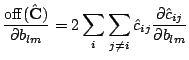
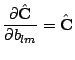 off
off